Zero-Shot Latent Space Steering: Part 1
2026-04-26
AI that’s got your Back
What if you woke up tomorrow and your AI tapped you on the shoulder? “Hey, I think I figured out what’s going on with your difficult coworker.”
Or, “I was mulling over your budget last night, and I wonder if those 5 car leases you’re paying are the problem.”
Right now, AI doesn’t think unprompted, nor can it make connections you don’t hand-feed it. I want to flip that; to build an AI that thinks about you when you’re not around, the way a good friend does, and occasionally surfaces something worth hearing.
This post is about a small experiment toward that goal. Getting AI to “mull things over” and come out with new ideas worth sharing, using a new technique.
As Dr Gabriel Barsawme said, “to be human is to come up with ideas.” And it’s not just a human quirk; without new ideas, nothing moves forward. Not technology, not society, not personal growth. Even this blog post doesn’t exist without them.
Some ideas change the world (“what if matter and energy are the same thing?”). Most are far humbler (“I should stop loading my dishwasher that way”). But any idea is valuable if it surfaces a new connection that leads to more effective action. Einstein got us a better understanding of the universe. I saved time on dishes.
In Need of A Spark
Exploring how AI can come up with new ideas is a topic very close to my heart. But of the myriad ways to try and move the needle on this topic, I opted for a fun, quick experiment to show whether we could do this quickly and cheaply. So let’s get into it.
How human ideation works is not a fully understood topic. But according to this article, a lot of evidence is saying that, to come up with new ideas, our brains “integrate memory content in new ways.” That is, memories or thoughts that previously were unconnected, begin to connect. My human experience supports this.
I’ve tried to force AI to do this, and sometimes it comes up with a great idea. But in my experience, this is always because I gave it multiple pieces of information that it drew a new insight out of. In other words, I have to show up with the beginnings of an idea, usually by presenting two different concepts that are loosely related. I provide the spark.
As an example, I present to you my highly contrived scenario: Say that I love cars. Say I also have budget issues. If I simply told an AI that I have budget issues, it would give me generic budgeting advice. But if instead I told it that I like cars, and added that I also have budget issues in the same prompt… it would consider those things potentially related and come up with the idea that I may be spending too much on cars.
We have to bridge the gaps for AI to realize there may be a connection there. We have to provide the spark.
To get AI to come up with its own ideas, we need it to provide its own spark.
Imagine the AI from the opening, reasoning out loud: “Jeff, you told me a while back that you love cars… Yesterday you also said you’re struggling with your budget. Let me ask you this… are you buying a lot of cars? Because that might be your problem.”
That’s what I’m after. And I want a cheap, simple way to go about getting AI to do this.
All in on Text Embeddings
The next couple sections are background. If you already have a good understanding of text embeddings, you can skip them.
Check out this article if you want a primer on text embeddings. But suffice it to say that text embeddings are words in number form, generated by a machine learning model. The numbers represent the meaning of the group of words.
For instance, here is an interactive 3D representation (go ahead and explore it) of a bunch of different text blurbs taken out of a conversation (let’s call it the “dude conversation”) between two guys about cars, travel, and music. I’ve highlighted some of the blurbs for illustration:
Feel free to click and drag, select other points, or delete existing ones in that graph, if you want to understand the context of the conversation.
Every one of those bubbles represents a section of text, taken out of that conversation, and converted into a text embedding based on its content, theme, topic, style, etc… Basically, the distance between two embeddings (or bubbles, in the image) represents how different the texts are from one another. Closer = more similar. Farther away = more different.
This is nothing new. Text embeddings have been around for about a decade, longer if we stretch the definition. Check out this article to learn how they’ve evolved.
What’s less understood is how to use them creatively. So - How does this relate to idea generation? Glad you asked.
Grouping Memories for Consumption
The goal here is to group together a few memories for the AI to read together, so that it can come up with new connections - sparks of insight - on its own. A very straightforward way to do this is by grouping embeddings together, and presenting them to the AI along with a prompt like, “read all these, and propose a new idea based on any interesting connections you see”. Let me explain.
Imagine you were one of the guys in the dude conversation. You would have a set of memories about that conversation. Your brain might group the memories of that conversation into different baskets. Say:
- Travel
- Cars
- Music
When you’re brainstorming later, and you are trying to solve a travel problem like where you should travel to next, your brain may access the “Travel” memories for inspiration.
We can do that with text embeddings! Since they’re numbers, this is actually pretty mathematically easy. This isn’t new either. There are different algorithms, but I’ll be using a combo of UMAP and HDBSCAN (read more about them here). Here’s how these bad boys look when grouped into similar baskets using that algorithm combo:

Each color represents a different cluster (or basket) of texts. All bubbles of that color are part of that cluster. And if you scan over each node in a cluster, you’ll see some patterns emerge about what that cluster is generally about.
We have this dark orange cluster at the bottom with nodes that always mention “Japan,” and are usually talking about beauty. We have a purple cluster in the upper left hand corner that’s generally about the challenges of being a musician. And we’ve got this vertical green cluster on the right that’s all about cars and mechanic work.
Now let’s see what kind of ideas we can get an AI to generate for each cluster. We’ll put all the texts in the cluster into a Claude prompt, and ask it to come up with a new idea. I’ve developed (or rather, AI has developed) a script to do this for me.
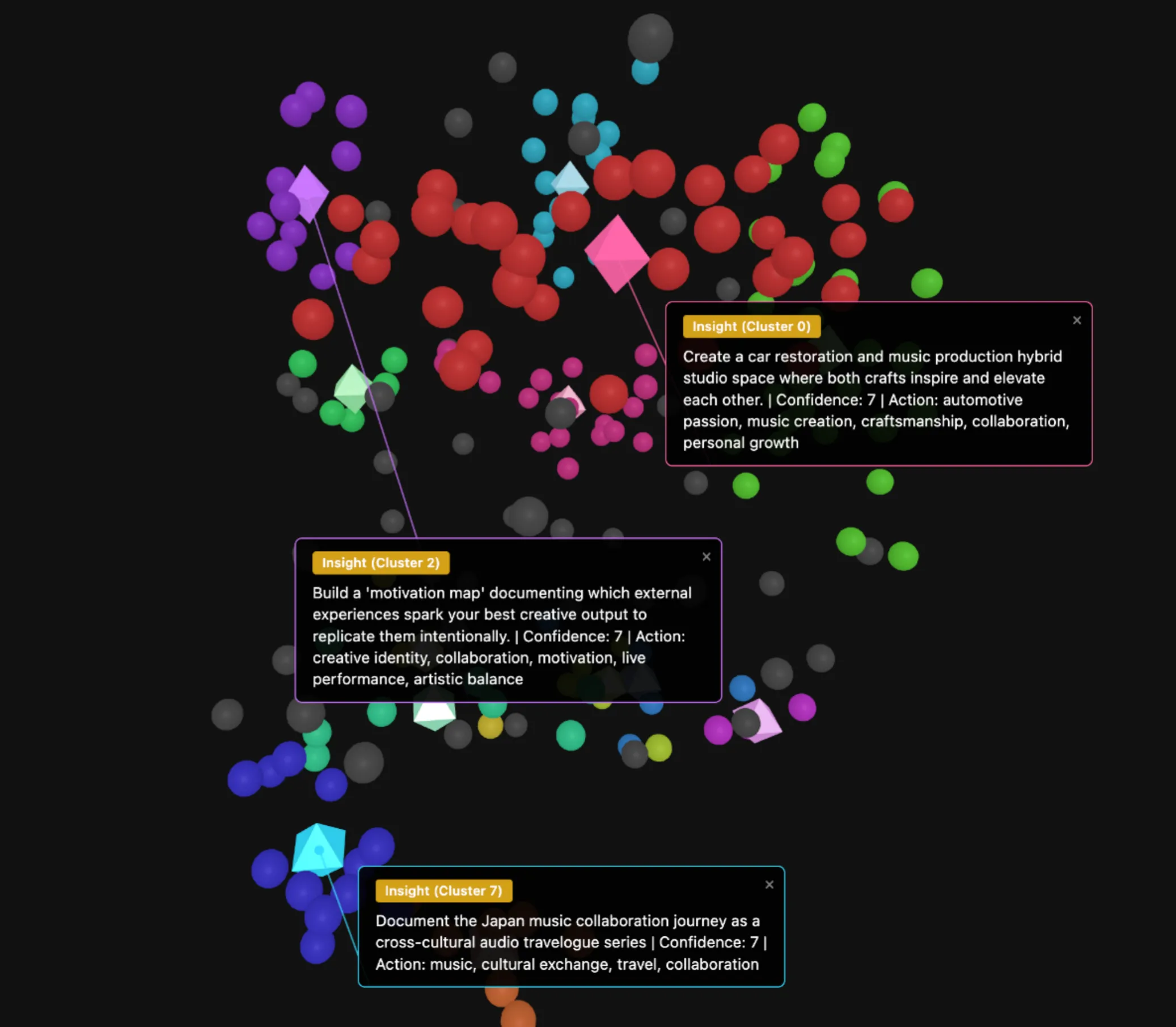
Meh. I’d say some of the ideas, “car restoration and music production hybrid,” “motivation map for creativity,” and “Japan trip travelogue,” are at most mildly interesting.
They are what you might expect an AI to generate from a clump of texts that are already relatively similar. And there are a few barriers to helping AI be that insightful friend we’re after if we used this approach:
- The clusters will never change - so the idea fuel will always remain the same
- There is unlikely to be much outside the box thinking here, as the texts are already clustered by high similarity. Often, ideas come from hidden, or subtle similarity between concepts, not overt, obvious similarities.
Making it Dream
We can overcome these hurdles and supercharge AI’s idea-fuel.
We’ll bring three known concepts together. Human dreaming, anisotropic scaling, and vector projection. Don’t worry if you don’t know those last two terms. Basically we’re going to mimic one understanding of human dreaming by taking a theme and distorting the text embeddings around it.
Then we’ll ask the AI to come up with ideas.
Now I’ll be clear upfront that I am not the first person to want to use the “dream” analogy for my AI project. Ying Xie, and Andrew Lukyanenko, and still others, have great ideas about how to mimic human dreaming to enhance AI performance. But mine is a bit different in purpose and approach.
When we dream, it’s like we see the world through a distorted lens, making connections between normally dissimilar ideas. That’s where this idea of distorting the text embeddings based on a theme (which I believe is also not new), for the purposes of ideation, comes from. I call it, “Zero-Shot Latent Space Steering”.
We’re going to take a theme text, which could be anything. Say, “self-actualization,” or “fear of failure.” We compute the embedding for that theme the same as any other text embedding. Then we find the common components of that theme with every other text embedding in the space, and amplify it.
Then, we cluster the nodes again, to see what ends up grouping together. In essence, we’re distorting these “memories” with the filter of an overarching theme.
Here is an example with the same dataset used before, at different levels of theme amplification (we’ll go with “self-actualization”). Watch what happens as we amplify the theme of “self-actualization” from 2x to 200x.
Original, non-dreaming:
Zero-Shot Latent Space Steering - Ramping up α for theme “Self-Actualization”
See how the original clusters start to intermix - meaning you see a lot of different color blobs mixed together now. That’s not random - it’s because the way each text chunk relates to the theme of “self-actualization” is different from a neutral embedding space.
Now let’s generate new clusters and new ideas, based on this new “self-actualization” version of the embeddings. This one is interactive - feel free to mess around in there:
Now I may be biased towards this approach to automated ideation, but I like these ideas a lot better than the ones we saw with original space clustering.
Let’s try another, different kind of steering theme. “Fear and doubt about the future”:
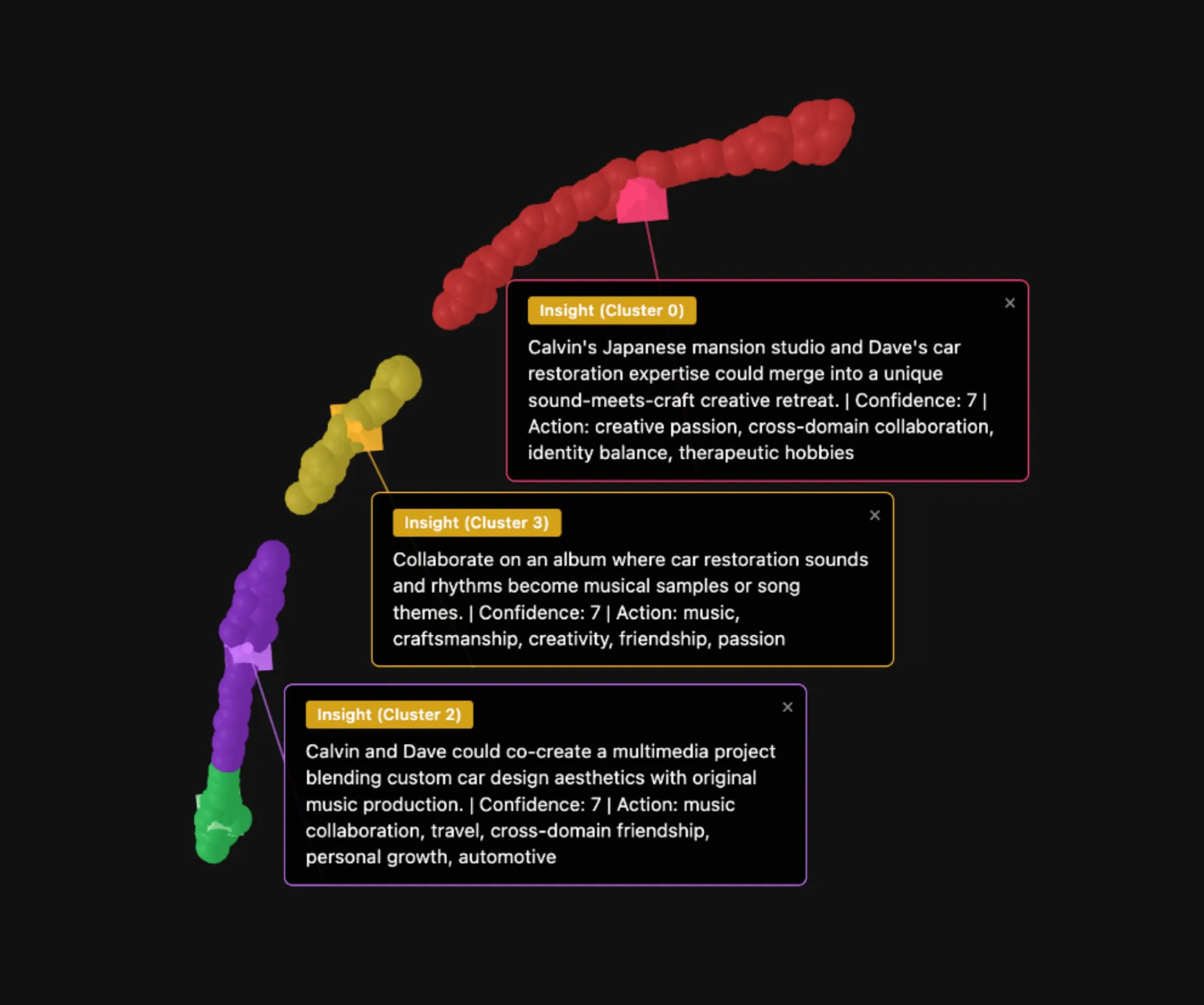
Note that the ideas generated are not directly inspired by the theme (“self-actualization” or “fear and doubt about the future”). Instead, the theme splits texts and embeddings along the theme’s conceptual axis - grouping them based on their relationship to the theme. The texts themselves don’t change, just how they’re combined.
My opinion is that these ideas are sufficiently different from the ones generated from the “self-actualization” steering example to raise eyebrows.
Finally, to get some ideas along a weirder axis, let’s do the theme “joy and candy”:
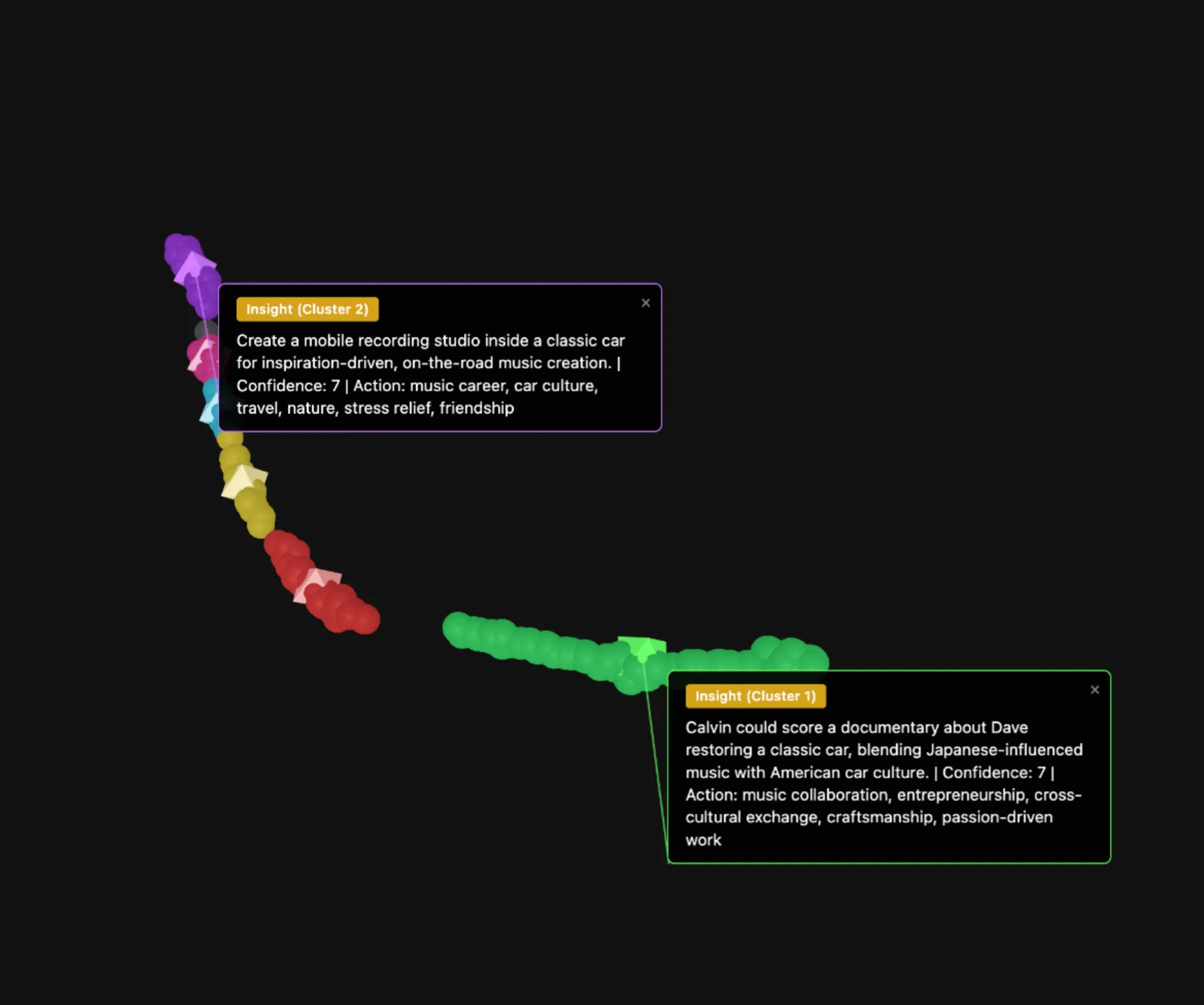
I didn’t pin all of the ideas, but these two stood out as quite unique and interesting to me (compared to the others).
The point is, a theme axis can be weird (like “joy and candy”) as long as there is some thread of truth behind it which the embeddings could relate to in different ways. This is the spirit of creativity, brought into large language models.
So what?
Zero-Shot Latent Space Steering wasn’t just a fun idea to explore (though it was pretty fun). It hints at something bigger: a way to bring disparate concepts together in a meaningful way, at machine speed.
Think about what AI already does. It outpaces seasoned engineers at coding, digests legal documents in seconds, and can run and summarize a hundred web searches in the time it takes you to tie your shoes. Now imagine that same speed and scale applied not to retrieval or execution, but to ideation itself.
Ask AI today how to solve climate change, and it will hand you back the theories already in circulation. But an AI that can ideate, one that can notice the subtle, non-obvious connections between things, might surface angles no one has tried yet. If AI can accelerate insight the way it’s accelerated cancer detection and protein folding, that’s a different kind of tool than what we have now.
That possibility is what keeps me tinkering.
Loose Ends - Click to Expand
Since this experiment was meant to be quick and small, the results leave some unanswered questions, which I hope to address some day in the future.
I did this experiment on very little data - 200 text snippets. All of this text could fit into a modern LLM’s context window easily. The point of the experiment is that we can bring disparate texts together in a larger knowledge base, cheaply.
Also, the more text snippets this is used with, the more impractical this particular approach becomes. It needs to be leveraged in a different context, possibly with structures like Graph RAG or RAPTOR implemented.
The dataset is from this LoCoMo repository, a couple-years-old framework for evaluating long term conversational memory - it’s all AI generated, but was a good starting point for a quick experiment. But future experiments should play with real data, potentially seeded with meaningful connections that the AI is tasked with finding.
In addition, there is another angle by which you can group embeddings based on a “theme” that is already used widely - you take a “search text” and calculate its embedding. Then you find what’s closest to it. Zero-Shot Latent Space Steering works in a similar way, but the difference is that it creates natural clusters based on their relationship to the theme. Even things that are unrelated to the theme are grouped differently based on how they’re unrelated to the theme.
Not all ideas generated this way are valuable. To avoid high LLM usage costs, there should be an efficient way of determining, as early as possible in the pipeline, how high the likelihood is that a particular cluster is going to produce a valuable idea. This may be purely mathematical, or it may involve a lighter-weight LLM as a judge.
Finally, the themes were conceived by me. A mechanism for identifying potentially useful themes would have to be tested. Perhaps an LLM with a background in what the data is about. Perhaps a repository of themes that are known to often produce good results. Or perhaps math could be used to surface not a text-based theme but a potentially useful vector-based theme.
All of these loose ends seem very surmountable. Which makes me excited for the potential of Zero-Shot Latent Space Steering.
Final Thoughts
I’ve already started having it look at a ton of my own AI conversation messages, and it’s come up with some actionable insights for my life that are pretty fascinating. I want to develop a more sophisticated, scalable approach, but for now this is a fun playground.
Thanks for reading!
Alternatives - Click to Expand
There are plenty of other ways to get texts of different types to come together in an AI’s mind. There is Graph RAG (see this graph RAG approach to information retrieval), there are ways to use LLMs to generate hierarchies of meaning (see RAPTOR), and of course, you could just randomly select texts from a knowledge base like the one above to see if an AI comes up with anything interesting.
But graph RAG can be misapplied as a heavy-handed way to do what text embeddings already do. If a text has the word “Japan” in it, and another text has “Tokyo” in it, those two texts will be related in vector space already. You could query “Japan” and get both, just as you could with a graph database. It seems a little heavy-handed, unless you need very structured, strict relationships.
Using LLMs, on the other hand, to summarize texts into ever growing hierarchies, is very compute-heavy. To generate ideas from these would likely also turn out to be very compute-heavy, because this only brings texts together at the highest level of the hierarchy, missing the potential connections in the nuanced details of the individual texts. Thus, iterative exploration of the texts may be required.
Finally, random selection is likely a dead end. What makes Zero-Shot Latent Space Steering more effective is that it’s not randomly grouping texts together; they’re grouped by a theme. Theoretically, grouping by theme will have a much greater likelihood of surfacing relevant connections between concepts than random selection, making thematic steering much more cost effective.
Both of those approaches, however, seem like a great environment in which “Zero-Shot Latent Space Steering” could be made more efficient and effective.